

Pandas adalah sebuah paket library pada python yang digunakan untuk mempermudah dalam mengolah dan menganalisa data-data terstruktur. Pandas merupakan paket penting yang wajib diketahui untuk seorang data engineer, data analyst dan data scientist jika ingin mengolah dan manganalisa data menggunakan python. Jika kamu telah terbiasa menggunakan SQL, maka tidak akan sulit untuk membiasakan diri menggunakan fungsi-fungsi pada Pandas.
Panda memiliki format data yang sering digunakan, disebut DataFrame. Pandas DataFrame adalah struktur data 2 Dimensi. Data distrukturisasi seperti tabel yang berisi baris dan kolom, sehingga mudah untuk melakukan queri atau mengakses data tersebut. Baris merepresentasikan record dan kolom merepresentasikan field.
Saya tidak akan menjelaskan secara detail apa itu Panda, karena sudah banyak dibahas dimana-mana. Yuk langsung saja kita KODING !
Dataset
Dataset yang akan digunakan adalah dataset yang sederhana, sehungga lebih mudah untuk memahami Pandas. Data diambil dari Badan Pusat Statistik (bps.go.id). Dataset tersebut memuat beberapa informasi tentang provinsi di Indonesia pada tahun 2015. Dataset ini memiliki 10 kolom:
- province: nama provinsi di Indonesia
- rainfall: jumah curah hujan dalam mm yang diambil dari stasiun pengamatan yang dimiliki BMKG
- rainy_day: jumlah hari terjadinya hujan dalam setahun
- expenses_food_urban: rata-rata pengeluaran perkapita dalam sebulan untuk makanan di perkotaan
- expenses_other_urban: rata-rata pengeluaran perkapita dalam sebulan untuk barang non makanan di perkotaan
- expenses_food_rural: rata-rata pengeluaran perkapita dalam sebulan untuk makanan di pedesaan
- expense_other_rural: rata-rata pengeluaran perkapita dalam sebulan untuk barang non makanan di pedesaan
- unemployment: persentase angka pengangguran bulan agustus
- time_zone: klasifikasi zona waktu
- island: nama pulau
Dataset dapat didownload pada github
Import Paket Pandas
Untuk menggunakan paket pandas kita harus melakukan import paket, dan memberikan nama yang lebih pendek seperti pd, dengan menggunakan perintah import as
import pandas as pd
print('Pandas version: {}'.format(pd.__version__))
dengan perintah "version" kita dapat mengetahui versi pandas yang kita gunakan. Versi Pandas yang digunakan pada tutorial ini adalah versi 1.1.0
Membaca File csv
Dataset yang digunakan adalah data-provinsi-2015 dataset yang telah dijelaskan sebelumnya dan berada pada github.com/project303/dataset. File dataset ini memiliki format text dengan tab sebagai pemisah antar kolom dan memiliki header sebagai nama dari kolom.
Untuk membaca text file dengan delimiter menggunakan perintah read_csv().
url = "https://raw.githubusercontent.com/project303/dataset/master/data-province-2015.cvs"
df = pd.read_csv(url, sep='\t')
Jika file data-provinsi-2015.txt telah didownload terlebih dahulu dan berada di lokal komputer, maka url diubah ke directory dimana file tersebut berada, misalkan url="c:\dataset\data-provinsi-2015.txt"
Sample Data
Setelah berhasil diload ke dalam Pandas DataFrame, hal pertama yang biasa dilakukan adalah melihat contoh. Pandas menyediakan perintah head() untuk melihat 5 baris pertama dari DataFrame.
df.head()

Terlihat data beserta nama kolom dapat ditampilkan dengan baik
Untuk melihat lebih banyak data, perintah head dapat diberi parameter jumlah dataframe yang ingin ditampilkan. Sebagai contoh untuk menampilkan 10 records pertama dari DataFrame
df.head(10)
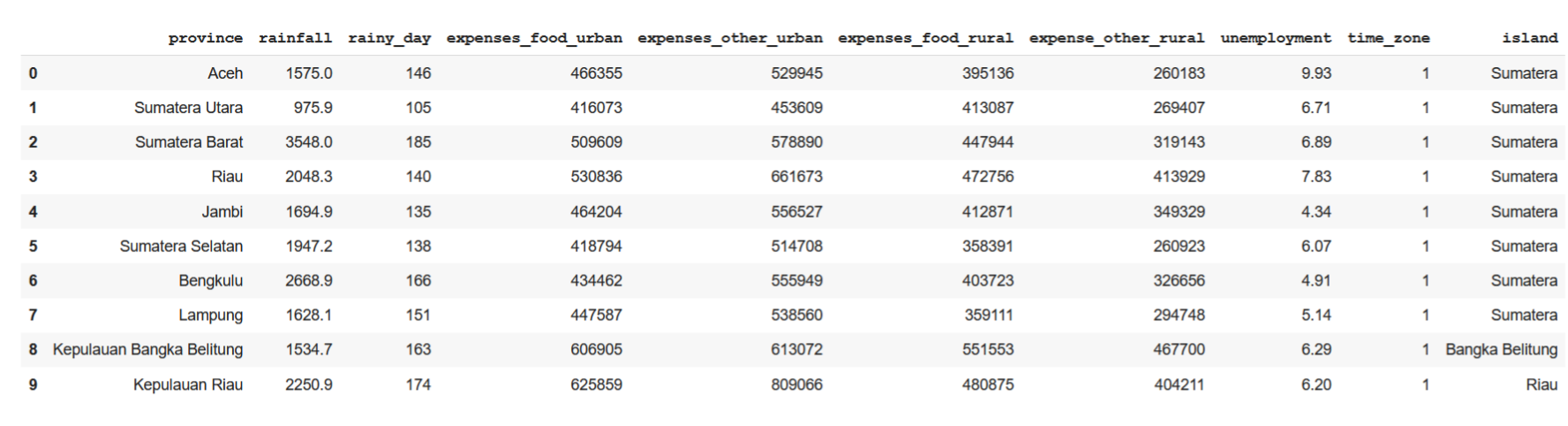
Untuk menampilkan n record terakhir, dapat menggunakan perintah tail(n). Jika tidak diberi parameter jumlah recordnya, maka secara default akan menampilkan 5 record
df.tail()

Fungsi sample() pada Pandas dapat digunakan jika kita ingin menampilkan dataframe secara acak. Misalkan menampilkan 10 dataframe secara acak
df.sample(10)

Jika ingin menampilkan seluruh data yang ada dalam DataFrame
df

Jumlah Data
Untuk memperoleh informasi jumlah records pada setiap kolom menggunakan perintah count()
df.count()

Fungsi count() akan menampilkan nama kolom dan jumlah baris/record. Seperti yang ditampilkan, semua kolom memiliki jumlah record yang sama, yaitu 34. Ini juga berarti bahwa tidak ada nilai null di semua kolom.
Cara lain untuk menampilkan jumlah record adalah dengan menggunakan property shape
df.shape[0]
Informasi Struktur Data
Property shape dapat digunakan untuk mengetahui dimensi dari dataframe
df.shape

Dari nilai property shape yang terlihat diatas, memberikan informasi bahwa DataFrame memiliki 34 baris/record dan 10 kolom.
Property DataFrame lainnya adalah dtypes, yang dapat digunakan untuk melihat struktur dari data
df.dtypes

Informasi lebih detail mengenai struktur DataFrame dapat dilihat menggunakan fungsi info()
df.info()

Informasi Statistik
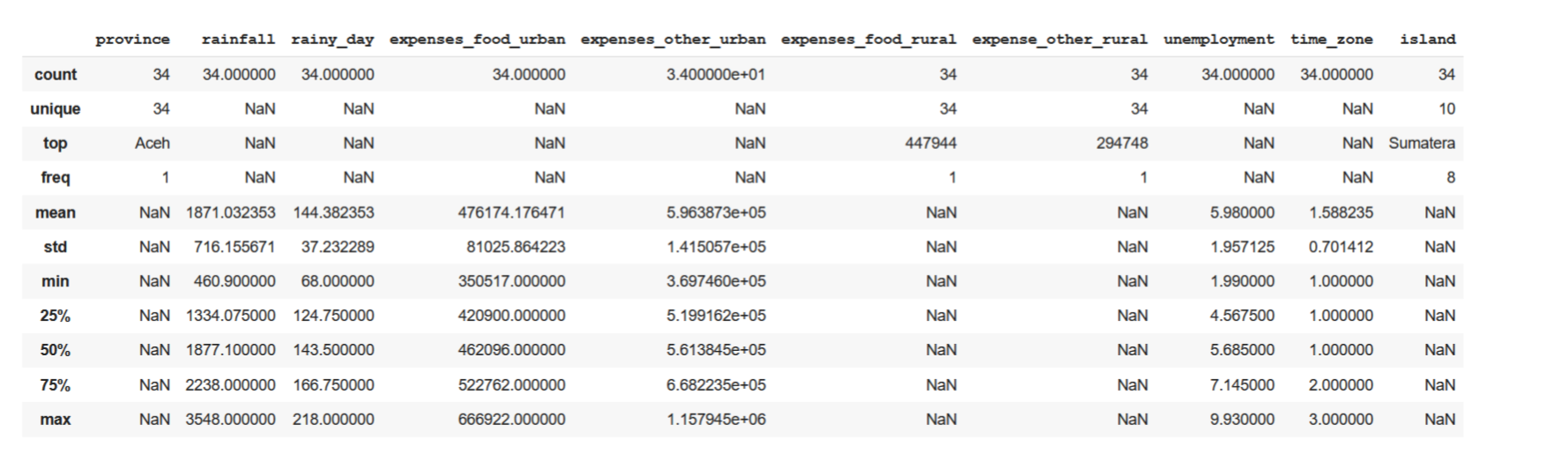
Informasi statistik untuk setiap kolom seperti nilai minimum, nilai maksimum, standar deviasi, rata-rata dan sebagainya, dapat ditampilkan dengan mengikuti perintah berikut
df.describe(include='all')
Menampilkan Kolom
Kita dapat memilih kolom mana saja yang akan ditampilkan, yaitu dengan menyebutkan nama kolom yang akan ditampilkan. Sebagai contoh kita hanya ingin menampilkan kolom province, unemployment dan expenses_food_urban
df[['province', 'unemployment', 'expenses_food_urban']].head()

Memfilter Data
Salah satu bagian penting yang digunakan dalam penyiapan data dan analisis data adalah filtering, yaitu pemilihan data dengan kriteria tertentu. Ini juga disebut data subset.
Bagi mereka yang terbiasa menggunakan SQL, ini adalah bagian dari pernyataan WHERE.
Misalnya, kami ingin menampilkan data untuk pulau yang sama dengan 'Sumatera'
df[(df.island == "Sumatera")].head()

Penggabungkan beberapa kondisi dapat menggunakan operator logika AND("&") dan operator logika OR("|") untuk memilih baris dengan lebih dari satu kriteria.
Misalnya kita ingin menampilkan semua provinsi yang ada di pulau Sumatera dan tingkat pengangguran kurang dari 5
df[(df.island == "Sumatera") & (df.unemployment < 5)]

Penulisan dengan cara yang berbeda tetapi memiliki hasil yang sama
df[(df['island'] == "Sumatera") & (df['unemployment'] < 5)].head()

Pada contoh di atas memiiki 2 kriteria, yaitu
- island = 'Sumatera'
- unemployment < 5
Penggunaan operator logika AND ("&") di atas, akan mengambil data yang cocok dengan kedua kriteria tersebut. Jika Anda ingin mendapatkan data yang cocok hanya untuk salah satu kriteria, dapat menggunakan operator logika OR("|")
Fungsi isin() dapat digunakan untuk memfilter kolom jika nilainya ditentukan dalam bentuk list/daftar. Misalnya, kami ingin menampilkan provinsi di Sumatera dan pulau Kalimantan yang memiliki tingkat pengangguran kurang dari 5
df[ (df['island'].isin(['Sumatera', 'Kalimantan']))
& (df['unemployment'] < 5)
]

Untuk penyataan negasi atau NOT menggunakan tanda '~'
df[ ~(df['island'].isin(['Sumatera', 'Kalimantan']))
& (df['unemployment'] < 5)
].head()

Hasil pernyataan diatas menunjukkan semua data yang TIDAK berada di pulau Sumatera dan Kalimantan, dan memiliki tingkat pengangguran kurang dari 5
Jika pernyataan kondisi terlalu rumit, maka sebaiknya dibuat variable DataFrame baru sehingga menyederhanakan proses berikutnya
df2 = df[ ~(df['island'].isin(['Sumatera', 'Kalimantan']))
& (df['unemployment'] < 5)
]
df2.sample(5)

Mengurutkan Data
Fungsi sort_values() digunakan untuk melakukan pengurutan data berdasarkan dengan kolom yang disebutkan mulai dari nilai terkecil. Perintah berikut untuk menampilkan data diurutkan berdasarkan kolom rainfall
df.sort_values('rainfall').head()

Atau menggunakan data yang telah difilter sebelumnya
df2.sort_values('rainfall').head(5)

Untuk mengurutkan data dimulai dari nilai terbesar, maka parameter ascending diberi nilai False
df.sort_values('rainfall', ascending=False).head()

Jika ingin mengurutkan data dengan menggunakan lebih dari satu kolom maka perlu ditentukan daftar nama kolom, misalkan mengurutkan berdasarkan kolom rainfall dan rainy_day, dapat dilakukan seperti berikut
df.sort_values(['rainfall', 'rainy_day' ]).head()

pada baris 3 dan 4 terlihat data memiliki nilai rainy_day yang tidak berurut, karena telah diurutkan berdasarkan rainfall terlebih dahulu
Setiap kolom juga dapat memiliki tipe pengurutannya masing-masing, misalkan time_zone diurutkan secara DESC dan rainy_day secara ASC
df.sort_values(['time_zone', 'rainy_day'], ascending=[0, 1]).head(10)

ASC : mengurutkan dengan nilai terbesar lebih dahulu
DESC: mengurutkan dengan nilai terkecil lebih dahulu
Jika ingin menampilkan hanya kolom time_zone, rainy_day, province, dan island

Rehat Sejenak
Mantap! Kamu telah selesai mempelajari BAGIAN 1 - Panduan Praktis Penggunaan Pandas. Semoga kamu mendapatkan ide betapa mudahnya Pandas. Pada bagian ini telah dipelajari tentang cara membaca data, mendapatkan informasi struktur, memfilter, dan mengurutkan data.
Nanti pada BAGIAN 2 - Panduan Praktis Penggunaan Pandas, akan dituntaskan semua hal-hal yang penting untuk diketahui pada Pandas. Akan dijelaskan bagaimana melakukan aggregasi, grouping data, manipulasi kolom, join antar data dan visualisasi data.
Artikel ini juga diposting pada medium
Versi notebook dapat diakses pada github
Untuk yang belum pernah menggunakan Python dapat membaca Berkenalan dengan Python
Enjoy learning and have fun with data !